
Technology
In 1980, Tim Berners-Lee wrote a personal hypertext notebook at CERN. The web was born from that impulse -- and then became an extraction machine. The protocols now exist to correct that.
Origins
It started as a personal notebook
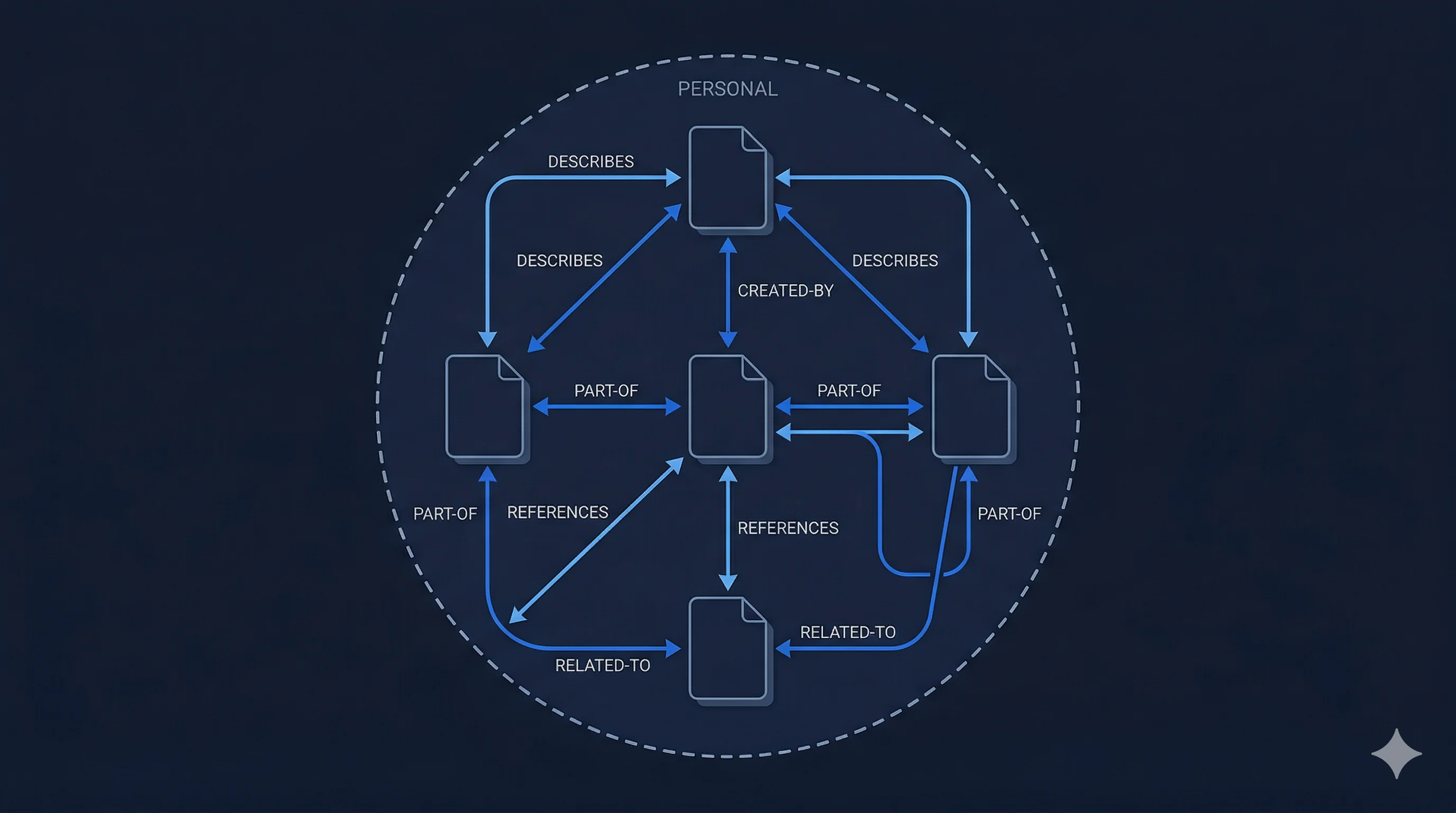
In 1980, a software consultant at CERN wrote a program called Enquire. It was a private hypertext system -- a way to track connections between people, projects, and documents. Nodes linked to other nodes through typed, bidirectional relationships. There was no network. No server. No audience. Just one person structuring what they knew.
That consultant was Tim Berners-Lee. A decade later, he would propose the World Wide Web -- a system that took Enquire's idea of linked documents and opened it to everyone. The web succeeded beyond anyone's imagination. But in the process, it abandoned the thing that made Enquire work: the person who wrote the data was the person who owned it.
That loss is the root of everything that went wrong.
The drift
What the open web became
The web succeeded because it was open. Anyone could publish. Anyone could link. No gatekeeper decided what was allowed. But openness without ownership created a vacuum. HTTP had no native concept of identity. No access control. No data portability. These were not oversights -- they were deliberate simplifications that made the protocol adoptable. Companies filled that vacuum with user accounts, cookies, and databases they controlled.
Two decades of this produced a specific economic structure. Your reading history, your bookmarks, your search queries, your social graph -- all stored on servers you do not control, governed by terms you did not negotiate, monetized in ways you cannot audit. Shoshana Zuboff named it surveillance capitalism: the unilateral extraction of human experience as raw material for prediction products.
There are two categories of data loss here, and the distinction matters. The first is data you gave willingly -- account signups, saved preferences, reading lists. You consented because there was no alternative architecture that let you own those things yourself. The second is data collected without your knowledge or meaningful consent -- cross-site tracking, browser fingerprinting, behavioral profiles assembled from metadata you never intended to share. Both feed the same machine.
Even the tools that appear to respect users -- Pocket, Notion, Raindrop, Instapaper -- hold your data on their servers, in their format, under their terms. They are better landlords, but they are still landlords. You cannot take your data and walk away without their permission. You cannot grant your own AI agent access to your own reading history without going through their API, if they offer one at all.
The problem is not bad actors. The problem is that the architecture of the web made data extraction the path of least resistance, and data ownership an afterthought that nobody built into the protocols.

Core technologies
The protocols that enforce ownership
Blogmarks is built on five open standards. Together they guarantee that your data is stored where you control it, structured so any tool can read it, and accessible to AI agents without leaving your device.
Solid (Social Linked Data)
W3CYour data lives in a Pod you own. Applications plug into your data; they never hold it.
Read more →Model Context Protocol
AnthropicA hosted MCP server gives any AI agent scoped, revocable access to your knowledge base.
Read more →Schema.org
W3CEvery saved asset is structured data that any search engine, agent, or tool can read natively.
Read more →RDF & Linked Data
W3CKnowledge is typed triples — self-describing, interlinked, and permanently machine-readable.
Read more →Apache OpenDAL
ApacheOne unified storage API across every backend. Swap providers without changing application code.
Read more →Web platform
The web platform, used correctly
Beyond the ownership-specific protocols, Blogmarks uses the web platform as it was designed to be used. No frameworks on top of frameworks. No proprietary extensions. Standards that have been stable for years, implemented correctly.
Progressive Web App + Share Target API
Installable on any device, works offline through service workers, receives shared URLs from any app via the Web Share Target API. No app store. No gatekeeper.
Service Workers + Workbox
Intelligent caching: CacheFirst for static assets, NetworkFirst for API calls. The app loads instantly from cache and updates in the background.
RSS 2.0
An open syndication feed with no algorithm, no account required, no tracking. Subscribe from any feed reader. The format is 25 years old and still the best way to follow content.
WebDAV
The HTTP extension protocol that Solid Pods expose for resource management. Read, write, list, delete -- standard HTTP verbs on web-addressable resources.
JSON-LD
The serialization format for Schema.org structured data. A script tag in HTML that makes content machine-readable. No runtime, no library, no build step.
Security
Security headers are not optional
Every response from Blogmarks includes security headers that restrict what the browser is allowed to do. This is not defense in depth -- it is the baseline. No tracking scripts. No third-party analytics. No fingerprinting.
| Header | Policy |
|---|---|
| Content-Security-Policy | Restricted connect-src and script-src. Only self, authentication endpoints, and explicitly trusted origins. |
| Strict-Transport-Security | max-age=31536000; includeSubDomains. All connections over HTTPS. No exceptions. |
| X-Frame-Options | DENY. The application cannot be embedded in iframes. Clickjacking is structurally impossible. |
| X-Content-Type-Options | nosniff. The browser will not MIME-sniff responses away from the declared content-type. |
| Permissions-Policy | camera=(), microphone=(), geolocation=(). Hardware capabilities are denied at the policy level, not just unused. |
Architecture
How it fits together
The Blogmarks architecture has four runtime components with strict separation of concerns. The ingestion pipeline writes. The MCP server reads. The Solid Pod stores. The browser extension triggers. They never cross boundaries.
A URL enters the system through the browser extension or mobile share sheet. The ingestion pipeline fetches the bytes, detects the content-type, runs the appropriate extractor (HTML, PDF, and more to come), and stores both the raw bytes and the extracted Markdown in the user's Solid Pod. It then indexes semantic chunks in a local vector store.
The MCP server -- a hosted Node.js Lambda -- queries the bookmark store on behalf of AI agents. It reads from DynamoDB for retrieval and applies per-connection scope rules. It never runs extraction logic. The ingestion pipeline never handles queries. The bookmark store is the only shared state between them.
This boundary is sacred. It means each component can be replaced, upgraded, or audited independently. It means the MCP server has no write path to your data. It means your knowledge base is never one monolithic system -- it is a pipeline with clean interfaces.

Design decision
Why the MCP server runs on Lambda
A local MCP server shifts operational burden to the user: they must install a binary, keep it running, and handle updates. A hosted Lambda shifts that burden to infrastructure — the server is always on, always current, and requires no process management on the client side.
This is a deliberate trade-off. The original design called for a self-contained Rust binary (ADR-004, ADR-005). That approach offered zero data egress and no cloud dependency. After validating the architecture, we chose the hosted path for the v1 product because the installation barrier of a local binary is too high for the target user — someone who wants AI-enriched bookmarks, not a runtime environment to manage.
The hosted Lambda does mean queries pass through AWS infrastructure. We mitigate the privacy impact through scoped tokens: each AI client gets a connection with the minimum data access it needs, independently revocable. Write access is opt-in and off by default.
The architectural boundary remains intact. The MCP server (Lambda) never runs extraction logic. The ingestion pipeline (Lambda + CrewAI) never handles queries. They share only the DynamoDB bookmark store. Each component can be audited, replaced, or upgraded independently.
For users who need local-first operation or direct DynamoDB access, the companion mcp-bookmarks project provides an alternative that can run entirely on-device.

Manifesto
Your assets. Your bytes. Your knowledge.
The things you read, watch, and listen to are part of who you are. They should belong to you -- not to the platform that happened to serve them, not to the startup whose database holds your reading history.
They should be legible to your tools, portable across apps, and available to your AI agents without asking anyone's permission.
A bookmark is not a URL. It is a pointer to bytes. Those bytes have a content-type, and the content-type determines how to extract meaning from them. Blogmarks resolves the pointer, fetches the bytes, runs the right extractor, and stores the resulting knowledge -- owned by you, in a Solid Pod, forever rebuildable.
Tim Berners-Lee's first program, Enquire (1980), was a private hypertext notebook -- local, personal, yours. Solid is Enquire reconstructed after watching what the open web became. Blogmarks builds on that correction.
“Knowledge you accumulate should compound for you, not for someone else's data business.”
